2025 ~ 2026 年会总结
2026-02-07
关注方向
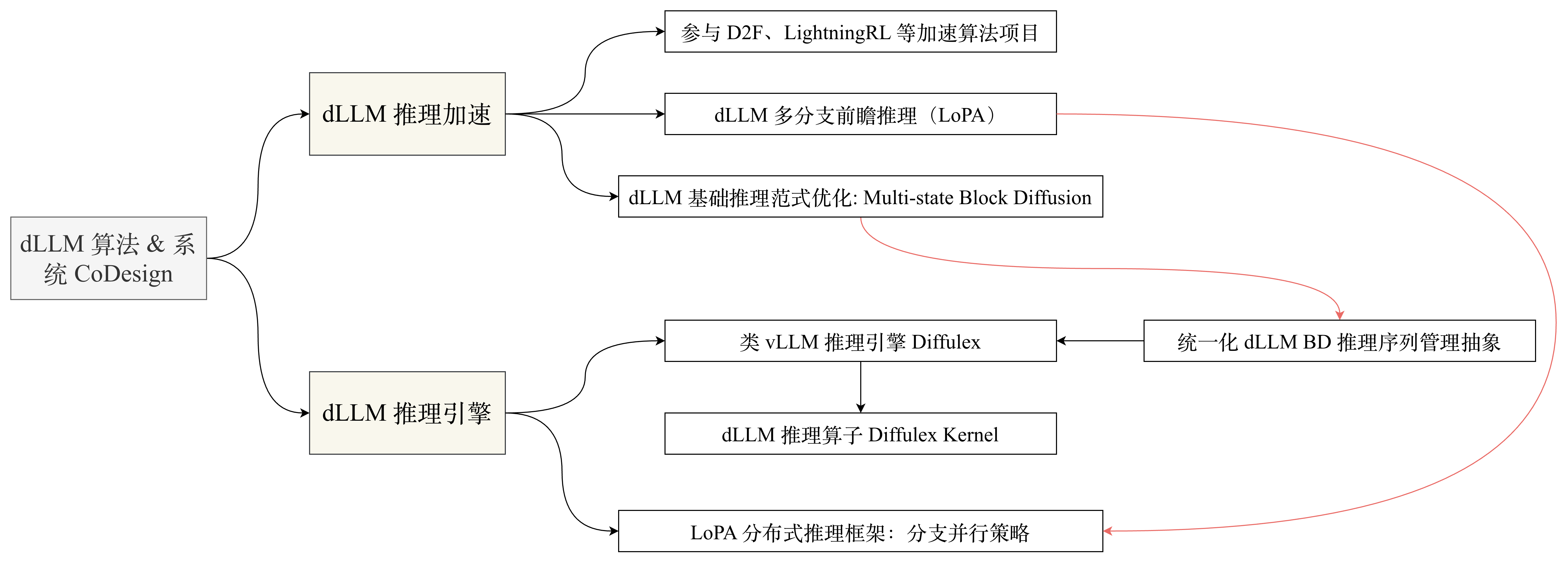
Discrete Diffusion Forcing (D2F)
参与过程
在项目中后期加入,主要负责实现 D2F vLLM 的实现。
前往 vLLM Shenzhen Meetup 现场进行分享。
收获与反思
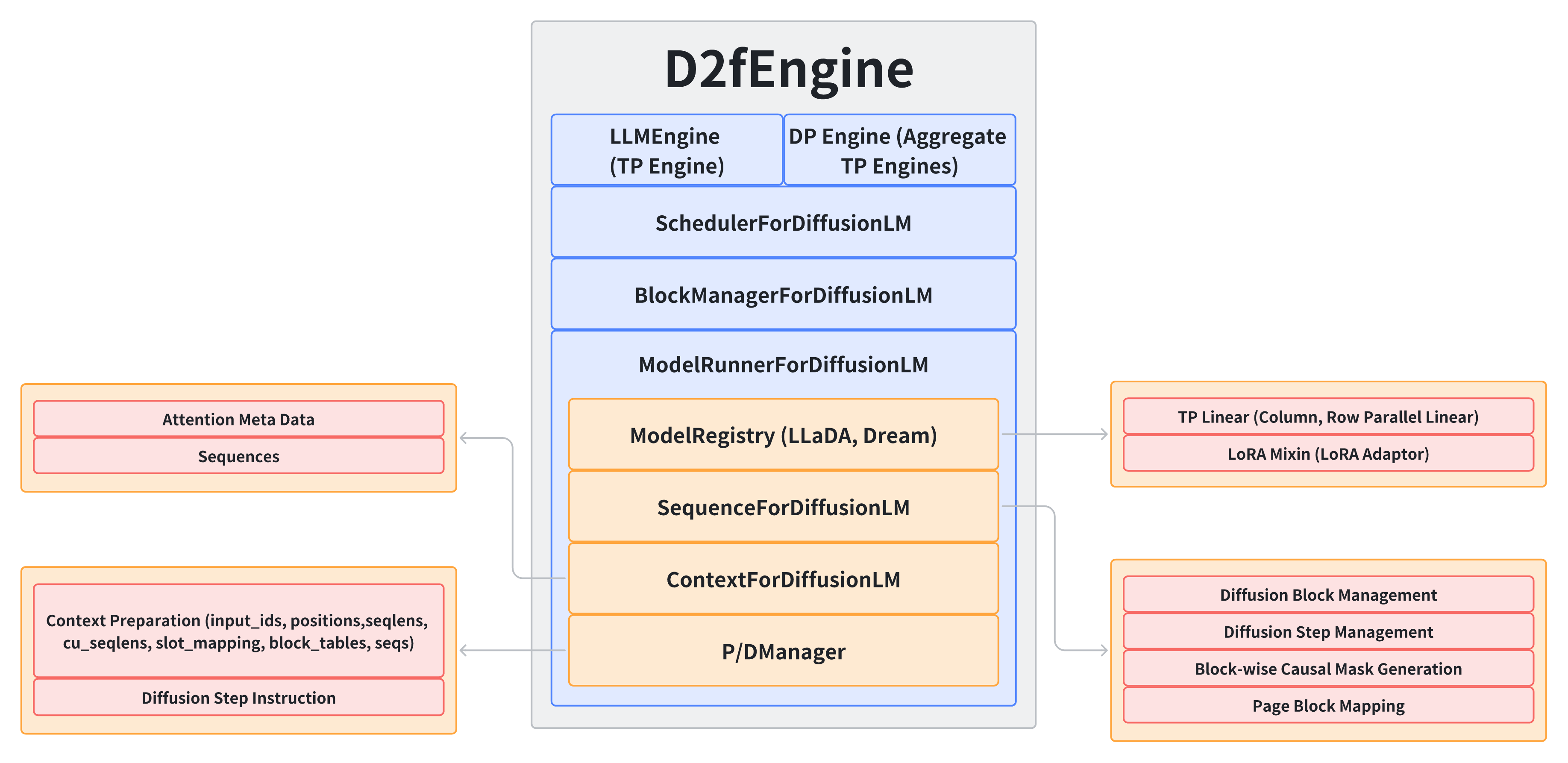
收获
- 从只是会用,到真正深入理解 vLLM 的原理、细节、实现方式、优化策略等。
- 深化了对 Kernel 的理解,能够根据需求设计 Kernel,并实现 Kernel,并保证 Kernel 和 Engine 的兼容性。
- 大幅提升了项目组织能力,虽然还不够。
反思
- 初期设计时,过多冗余代码,导致可读性不佳,且缺乏高效的单元测试,对目前重构带来较大难度(尤其是 D2F 部分)。
- 常常卡死在一些细节问题如 kernel 精度,sampler 实现细节,page 页表调度上。
Lookahead Parallel Decoding (LoPA)
参与过程
负责调整参数,辅助跑出 LoPA 的理论实验结果。
全权负责 LoPA-Dist 实现,设计 分支并行 和 两阶段 KV Cache 提交协议,实现高效推理。我的实现作为样板,辅助华为工程师实现 Ascend 设备上 1k tok/s 推理。
收获与反思
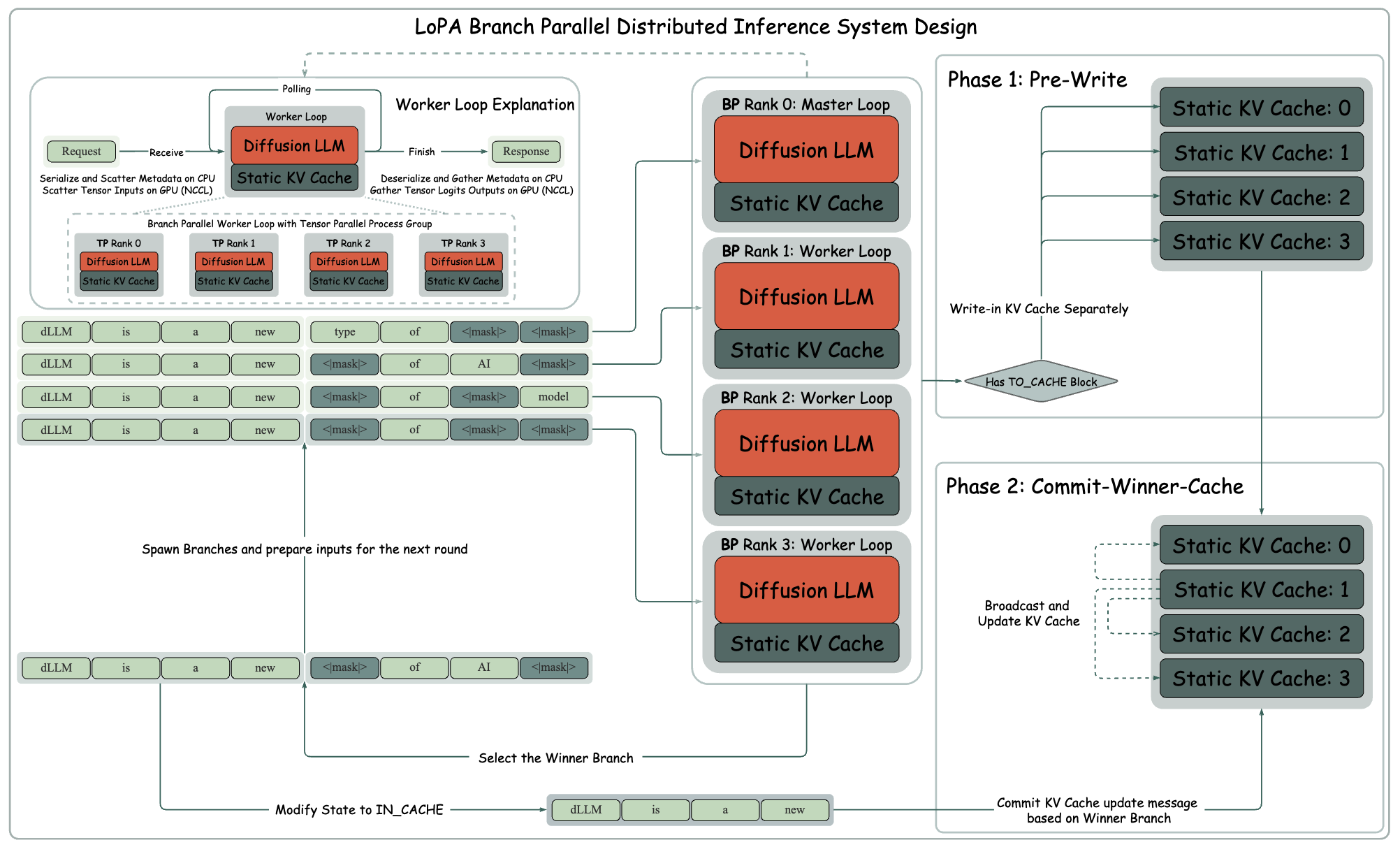
收获
- 充分锻炼了我的分布式编程能力,能够从设计到实现,从零完成一个分布式推理系统,并成功得到可观的加速。
反思
- 算法的 Pareto Frontier 过于理想化,实际使用中难以达到,尤其是过高的计算开销,是需要从算法设计阶段尽量避免的问题。
LightningRL: Accelerating dLLM via RL
参与过程
- 主要负责训练 SFT 模型,部分 RL 策略试错,以及评测。
- 辅助写论文,画图。
收获与反思
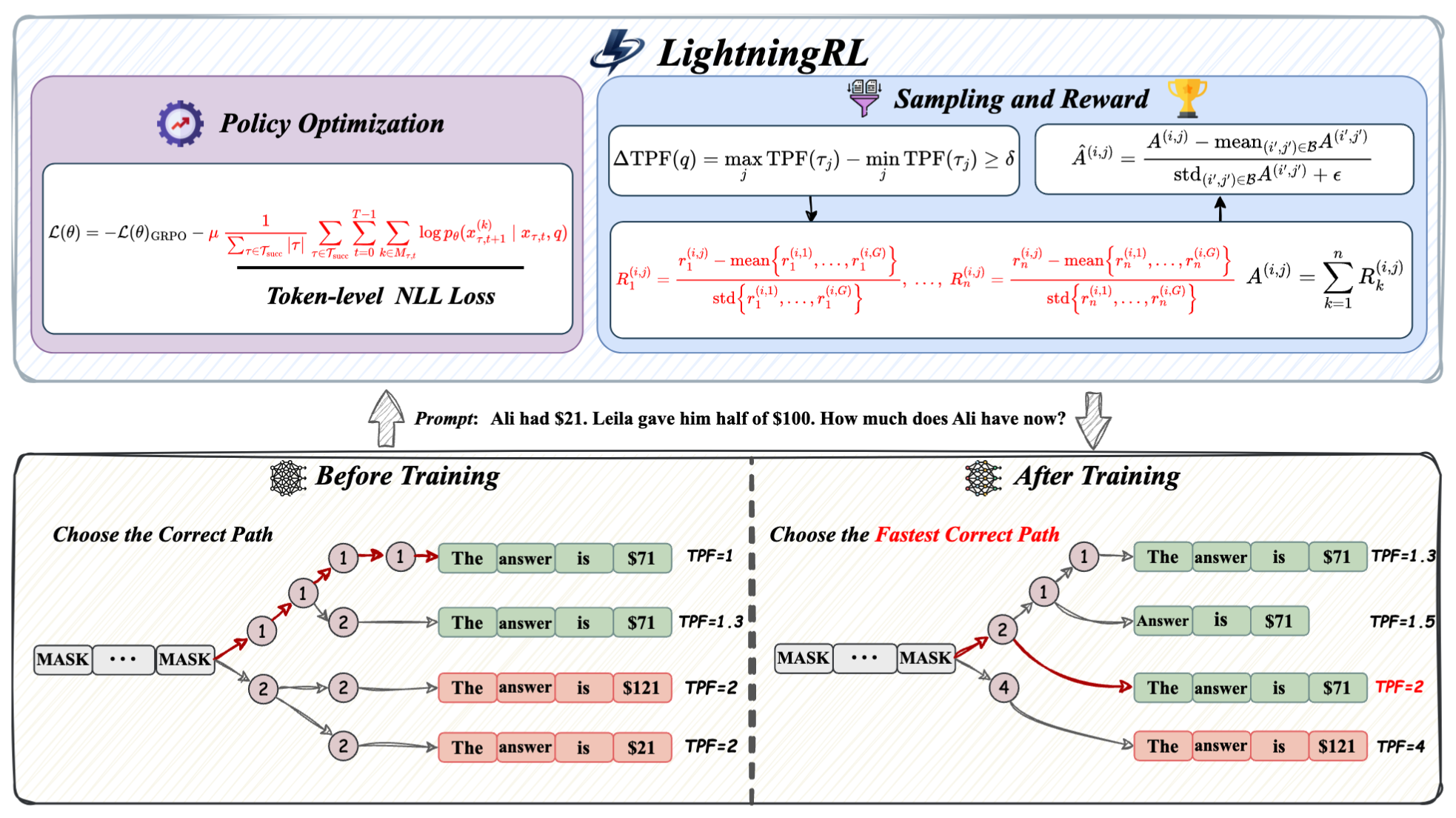
收获
- 结合 LoPA 认识到,算法在设计之初,不应该忽略系统实现的限制,若能在现有 Infra 基础上做到最佳优化,则优先考虑不修改任何结构的优化。
反思
- 个人对 RL 的原理理解不足,无法在实际算法设计上发挥作用,并且对 RL Infra 也不甚了解,这也许是下一步的学习、推进方向。
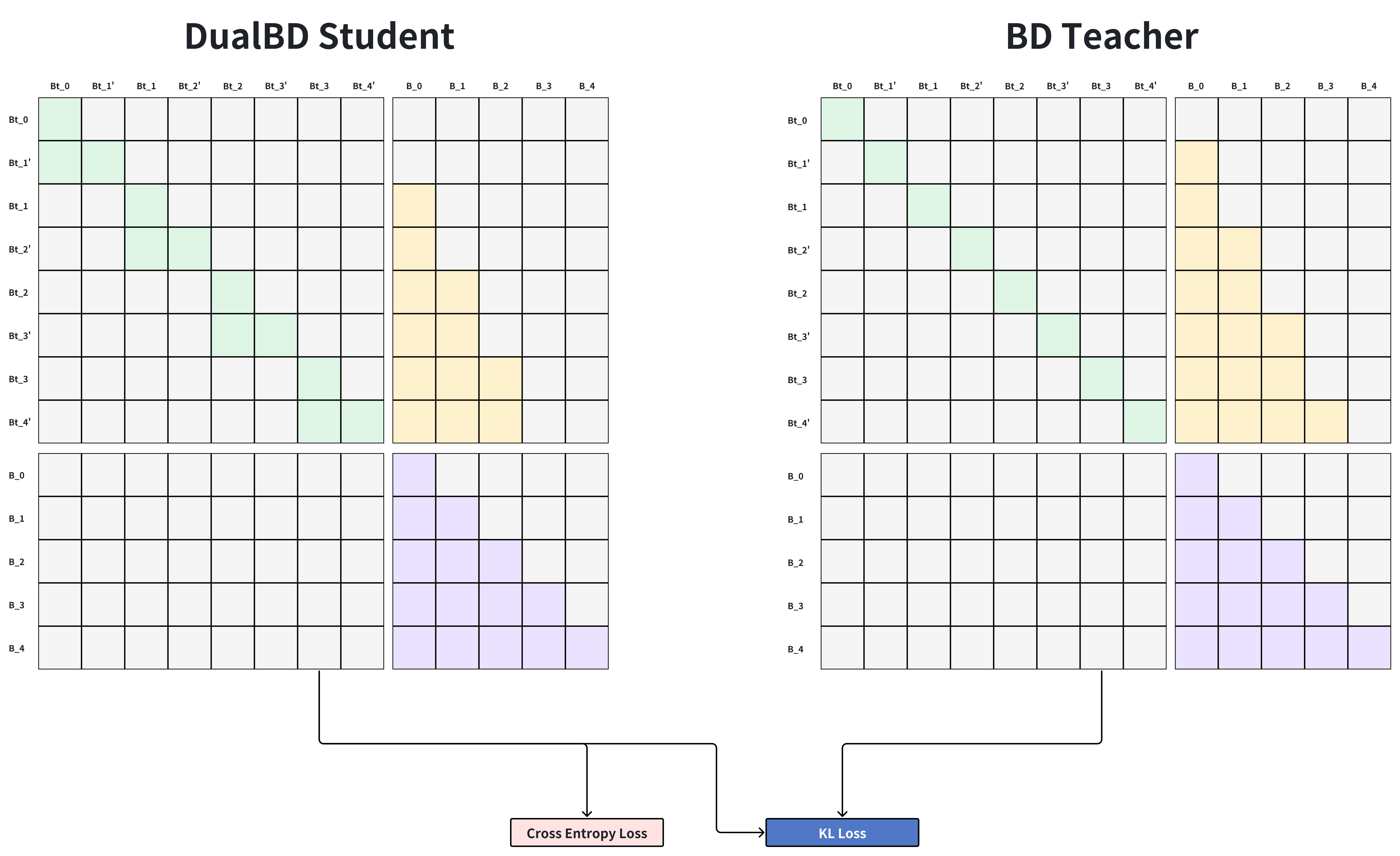
D2F-v2: Multi-state Block Diffusion (Tryouts)
参与过程
- 个人主导项目,目前完全由个人搭建完整实验 Pipeline(还没 Work,仍在探索中)。
收获与反思
收获
完整在 dLLM 领域从训练策略设计,到数据选取、清洗,再到分布式训练代码编写,再到评测,全部由个人完成。
首次完整由自己搭建自动化实验 Pipeline,因此得以充分分析实验现象,并拆解问题,从而尝试设计出优化的训练策略。
反思
- 个人对连续、离散 Diffusion 模型的理解均只在表层,在大规模调研论文的过程中,发现仍旧有很多公式无法快速看懂,如果不结合代码,甚至无法理解很多东西,想来这部分能力的欠缺长此以往定会限制个人发展,需要加强学习。
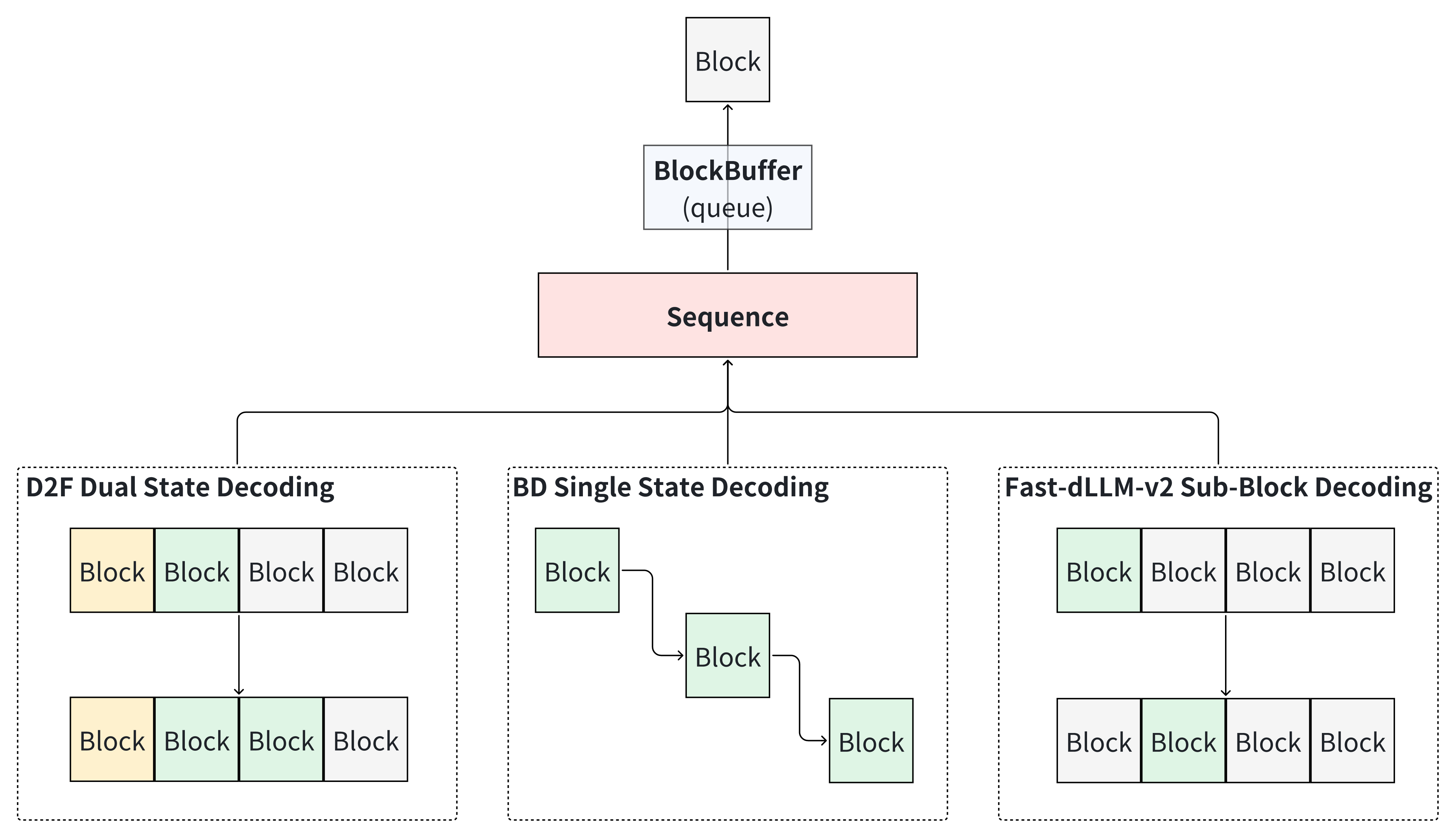
Diffulex: A Unified dLLM Inference Engine
参与过程
- 个人主导项目,实现了一个 dLLM 推理引擎(半成品),作为 MBD 的 Co-Designed Inference 后端。
收获与反思
收获
- 几乎全流程了解了 vLLM 的核心推理流程,对 vLLM 有了较为深入的理解。
- 从零开始设计了多种 dLLM 推理范式在 vLLM 上的实现,并成功跑通。
- 针对 dLLM 推理特性,设计实现了多个和引擎耦合的 Kernel,并成功跑通。
反思
- 项目一直缺乏一个明确的目标,对多种 dLLM 推理算法缺乏一个较好的统一化抽象,无法实现我们的灵活、可扩展目标。
- 始终会被各种事情卡死进度,由于书写该代码需要全身心投入,一旦开始就无法兼顾其他事情,反之亦然,因此项目难产。
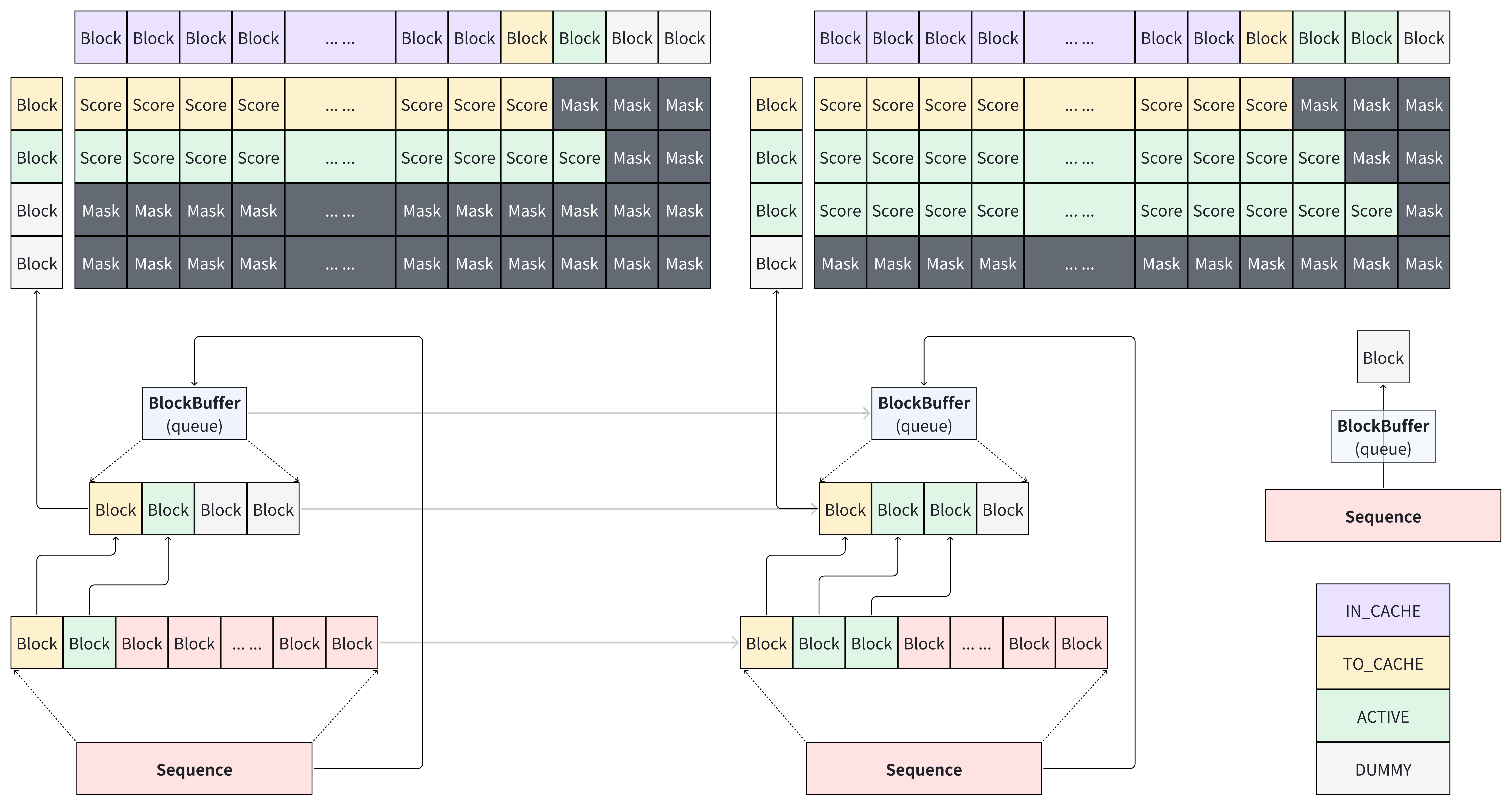
Unified Sequence Design for all Block-wise Causal dLLMs
基于 D2F-v2 的 MBD 设计过程得出的统一化抽象,希望该设计能够有效提升 Diffulex 的可开发性,并作为后续 D2F-v2 的推理后端,为 dLLM Infra 发展贡献核心设计理念。
未来要做的
