2026-03-17
核心目标
学会判断「当前 Token 是否已经稳了」
数据来源
特征与标签
收集成本
4×A6000,约 3 小时 完成全部数据收集
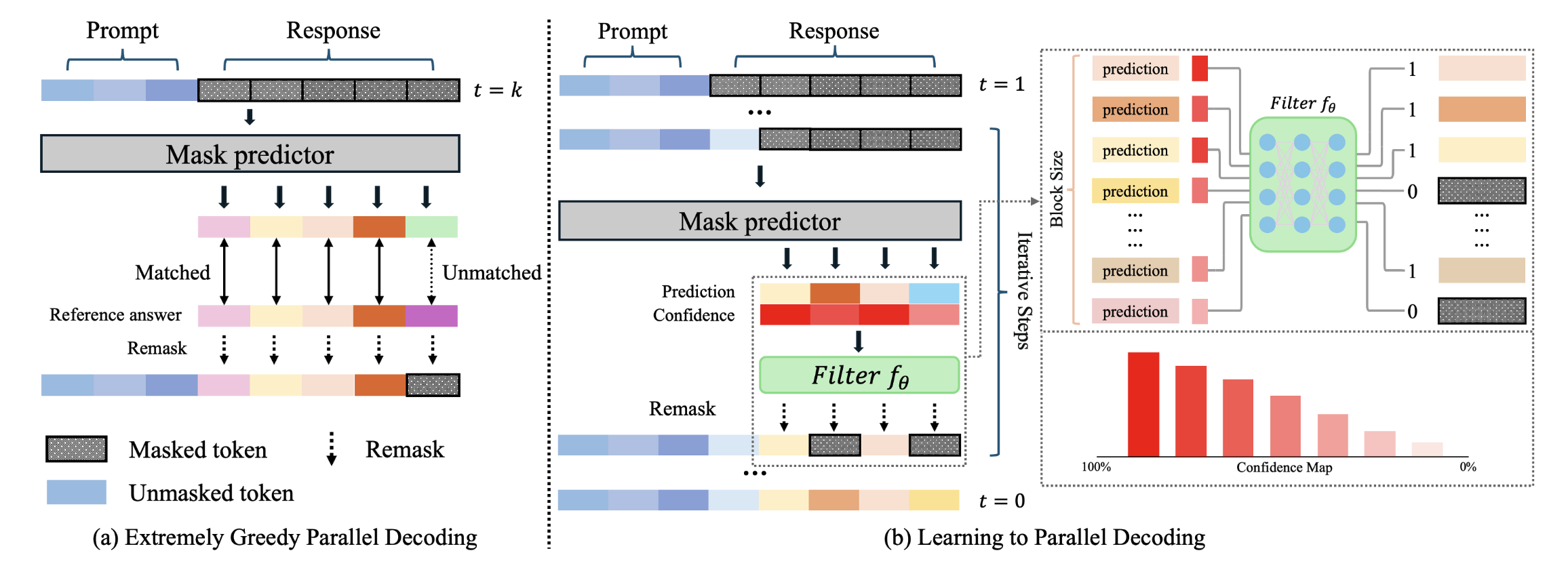
核心思想
不动 dLLM,只训练一个 2 层 MLP 作为过滤器
模型架构 (Filter Model \(f_\theta\))
损失函数 (BCE Loss)
\(L_{\text{BCE}} = -\frac{1}{m} \sum_{i=1}^m \left[ y_i \log \sigma(z_i) + (1 - y_i) \log(1 - \sigma(z_i)) \right]\)
训练开销(极小)
一句话总结
把复杂的解码控制压缩成几千参数的 二分类小头,便宜又好训。
无参考答案场景
训练好的 MLP 过滤器 \(f_\theta\) 充当「裁判」
执行流程
[MASK]
核心优势
高优策略造数据 → 超小 MLP 训裁判 → 毫秒级裁决,避免无意义反复解码
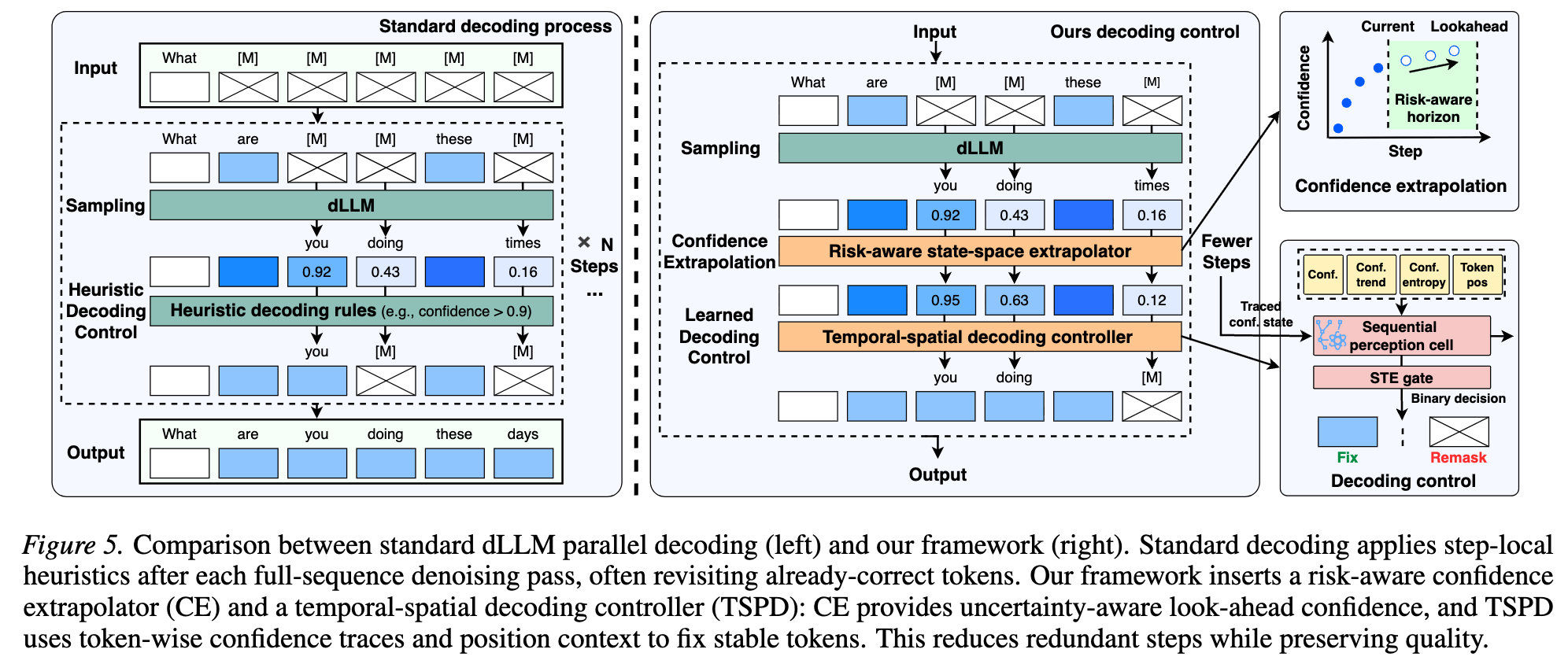
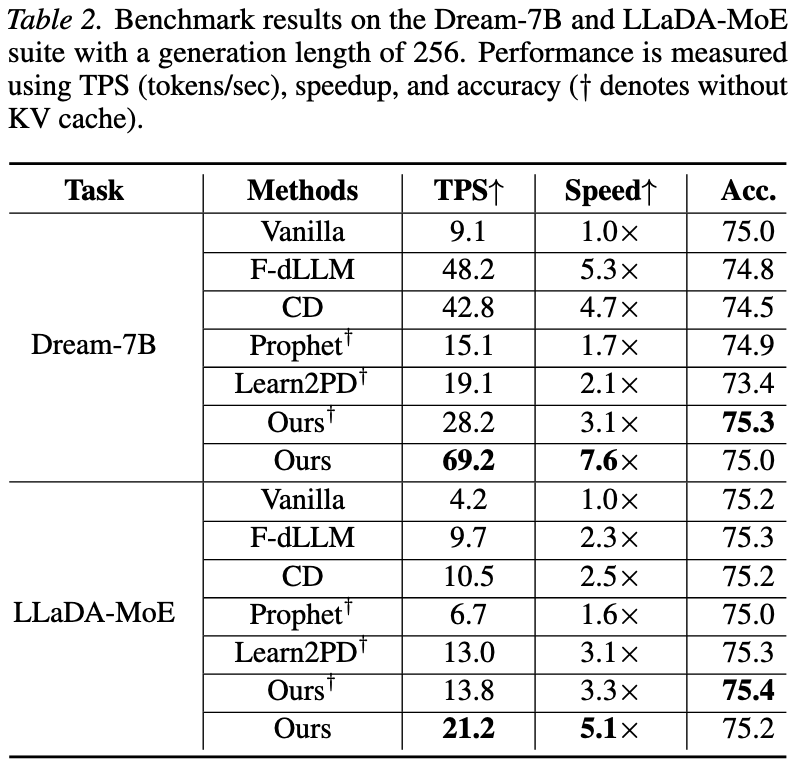
1. 时空并行解码 (TSPD)
2. 置信度外推 (CE)
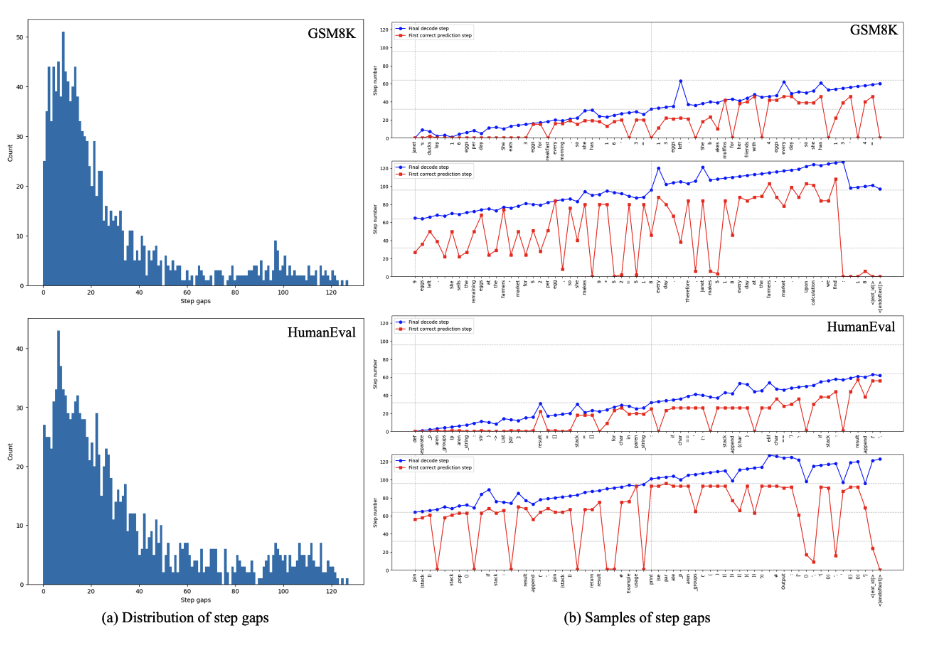
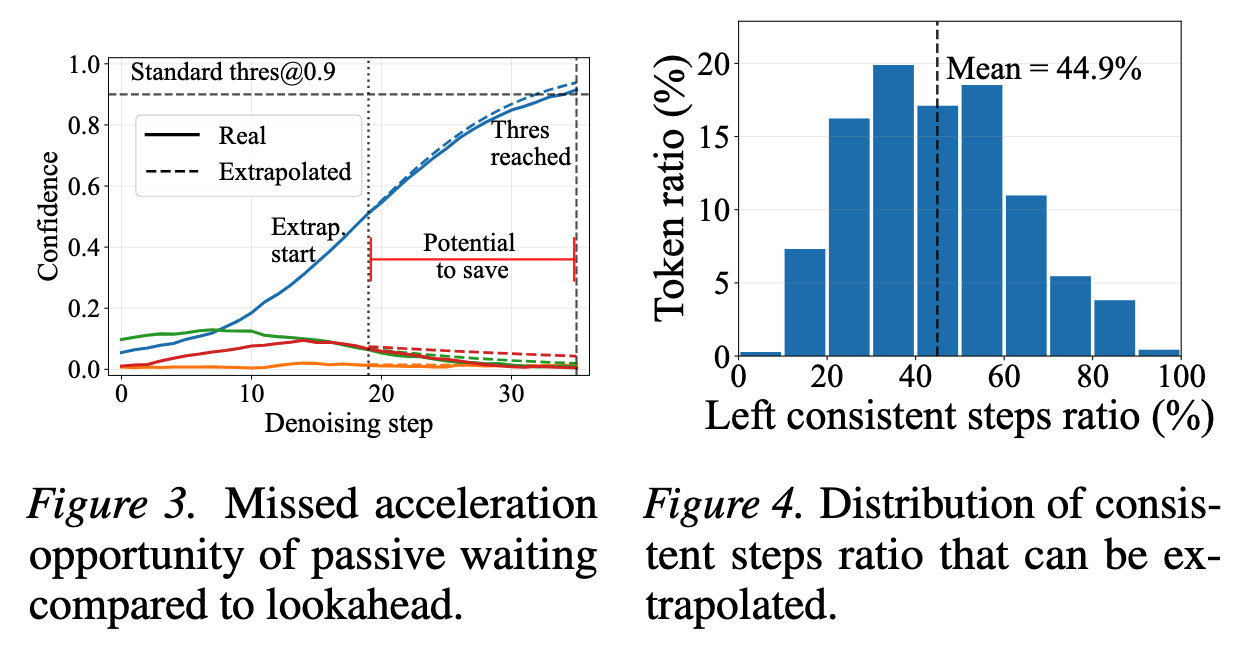
被动等待
其他关键不足
总结
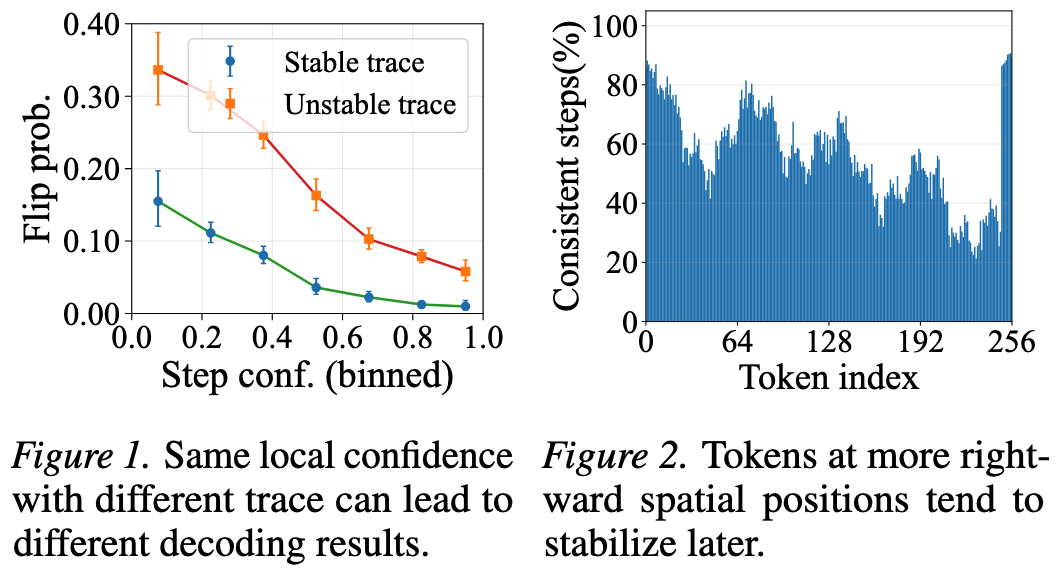
现有方案将扩散解码视为独立阈值测试,而非动态控制问题;在处理非对齐置信度与位置异质性时乏力。
Part 1 时空特征向量 \(r_i^{(t)} = [p_i^{(t)}, H_i^{(t)}, \Delta \bar{p}_i^{(t)}, \phi(i)]\) - 置信度、熵、动量/趋势、相对位置,综合时间轨迹与空间异质性
Part 2 序列感知控制器 \(h_i^{(t)} = f_{\psi}(h_i^{(t-1)}, r_i^{(t)})\), \(z_i^{(t)} = W h_i^{(t)} + b\) - 2 层 LSTM(~2k 参数)记忆历史轨迹,输出 Logit
Part 3 动作决策 \(a_i^{(t)} = I(\sigma(z_i^{(t)}) \geq 0.5)\) - \(a_i=1\) 锁定;\(a_i=0\) 继续去噪;用 STE 解决离散可微
训练 \(L_{gate} = \text{BCEWithLogits}(z_i^{(t)}, y_i^{(t)})\),\(y_i^{(t)}\) 为 Oracle 标签(当前预测与最终一致则为 1)
对比:传统方案用 \(p_i^{(t)} > \tau\) 静态阈值,单步快照、易误判;TSPD 用 \(f_{\psi}(\text{Trace}, \text{Position}) \to \{0,1\}\) 动态控制,看轨迹、更鲁棒
亮点
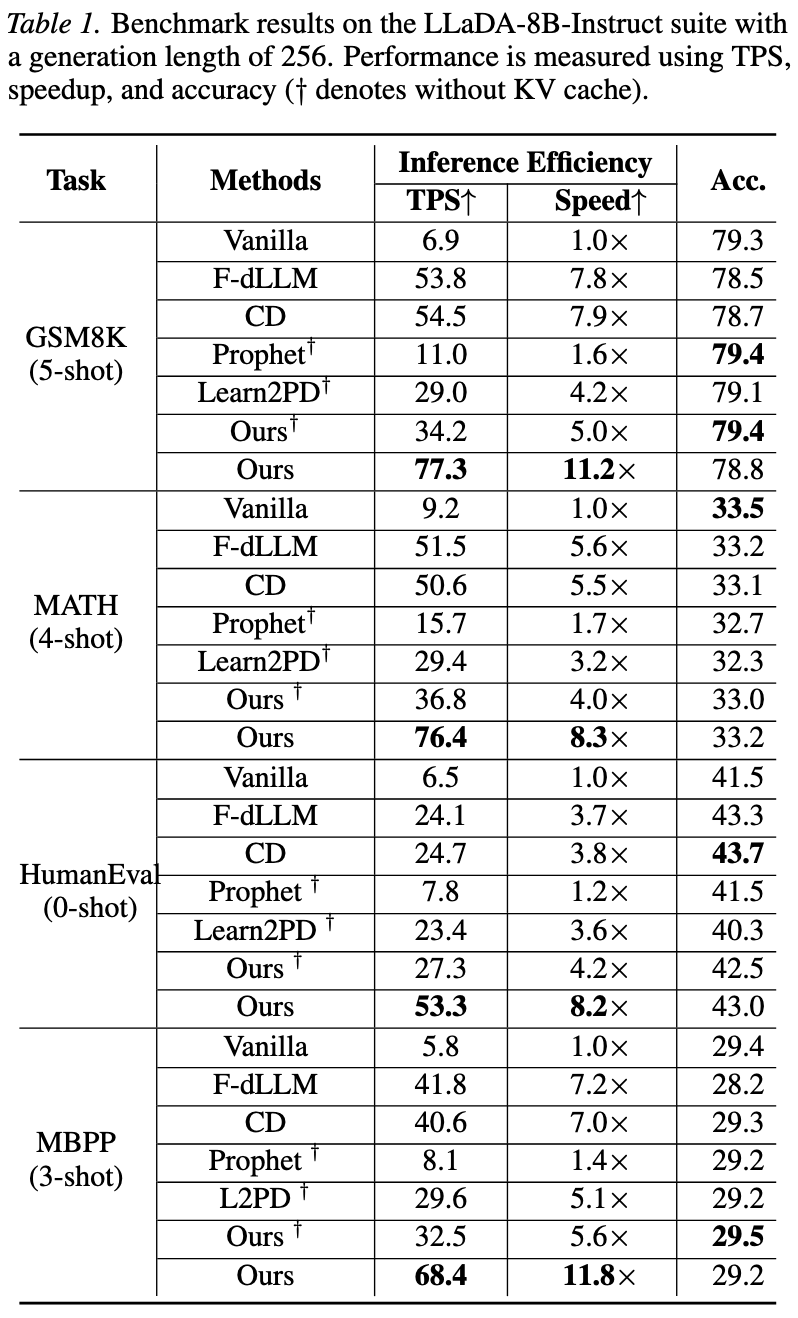
5k epoch:损失由 ~0.7 速降至 ~0.28 后平稳收敛;验证略高于训练且无分叉,表明轻量控制器有效收敛、泛化偏差小、未过拟合。
A. 基础瞬时
B. 时间趋势
C. 空间与不确定性
1. 动机:被动等待 vs 主动预测;用历史轨迹预测未来稳定态,实现「抢跑」
2. 状态空间模型 - 状态 \(x_i^{(t)} = [\delta_i^{(t)}, \dot{\delta}_i^{(t)}]^\top\)(边际 \(\delta\) + 变化率) - 转移 \(x_i^{(t-1)} = A x_i^{(t)} + \epsilon\),\(A = \begin{bmatrix} 1 & 1 \\ 0 & 1 \end{bmatrix}\)(常速) - 观测 \(o_i^{(t)} = \delta_i^{(t)} + \eta\);Kalman 在线估计
3. \(h\) 步预测 - \(\hat{x}_{t+h|t} = A^h \hat{x}_t\);\(P_{t+h|t} = A^h P_t (A^h)^\top + Q_h\) - 步数越远,\(\sigma^2_{t+h}\) 越大
4. 风险感知决策 - 保守下界 \(\text{LB}_{t+h} = \hat{\ell}_{t+h} - z \cdot \sigma_{t+h}\)(\(z\) 风险系数) - 动态地平线 \(h_{\text{pot}} = H \cdot r_t(j)\),\(r_t\) 由 left_coverage 决定
5. 实现与价值 - Training-free;输入 \(\delta_i^{(t)}\)(Top-1 与 Top-2 边际);开销 0.13% - 加速比再提升 0.5x~1.5x(GSM8K: 4.4x→5.0x)